5.12.11.28. Classify
electrical parts: Additional modules 5.12.11.28.2.
Enrich catalog with PDT information
|  |
| Prev | Next |
You can use the Enrich catalog with PDT information function to automatically make PDT information available in your catalog. The prerequisite for this is an appropriately prepared Excel file.
![[Note]](https://webapi.partcommunity.com/service/help/latest/pages/cn/partsolutions_user/doc/images/note.png)
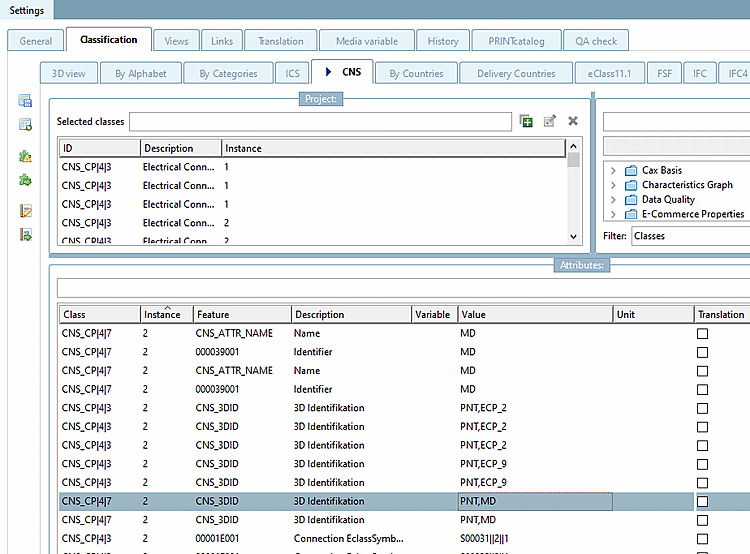
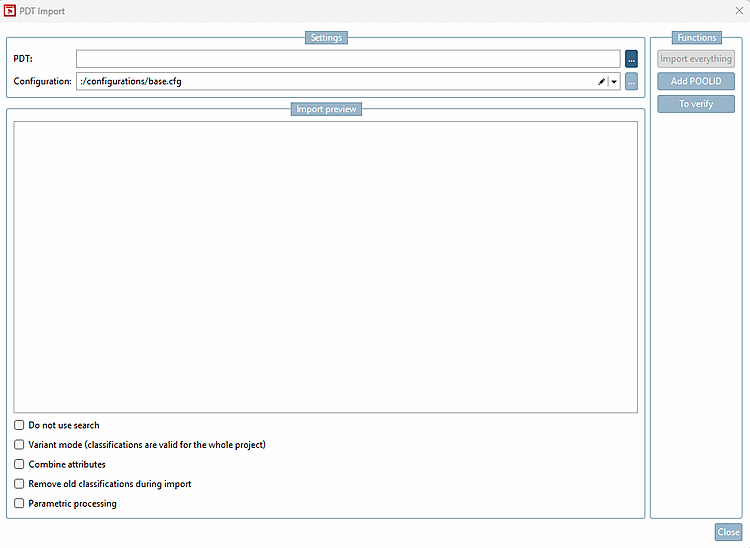
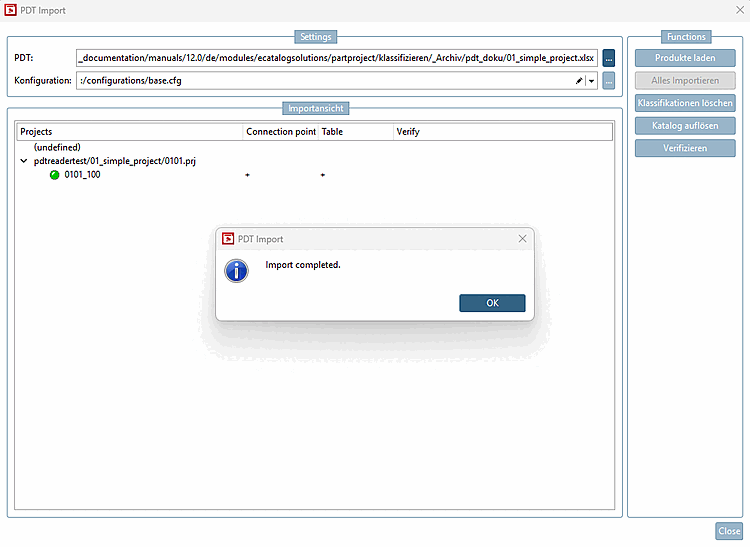
Call up the PDT Import dialog under Automation -> Enrich catalog with PDT information.
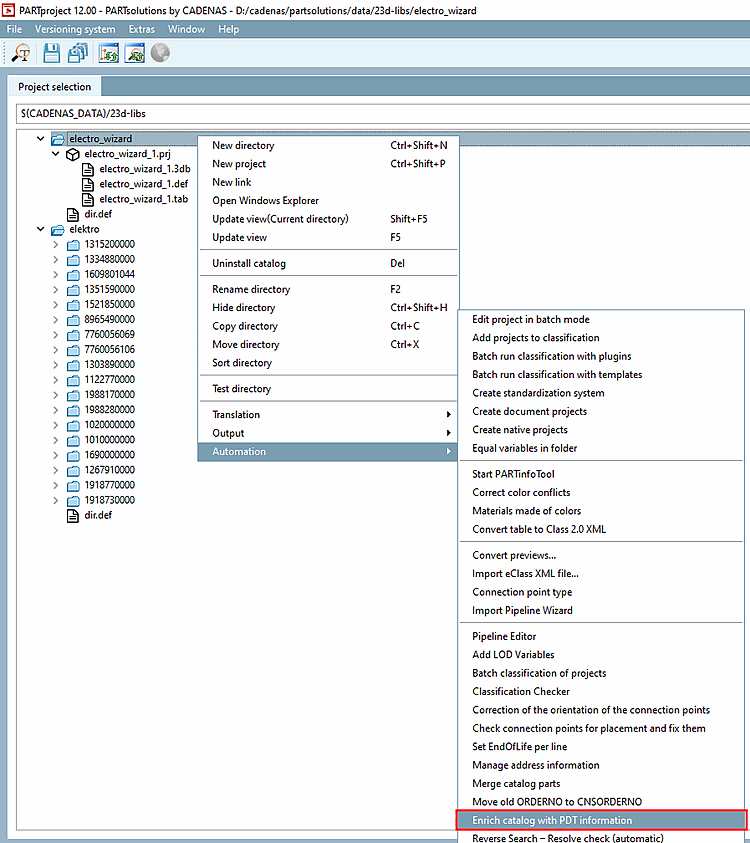
-> The PDT Import dialog opens.
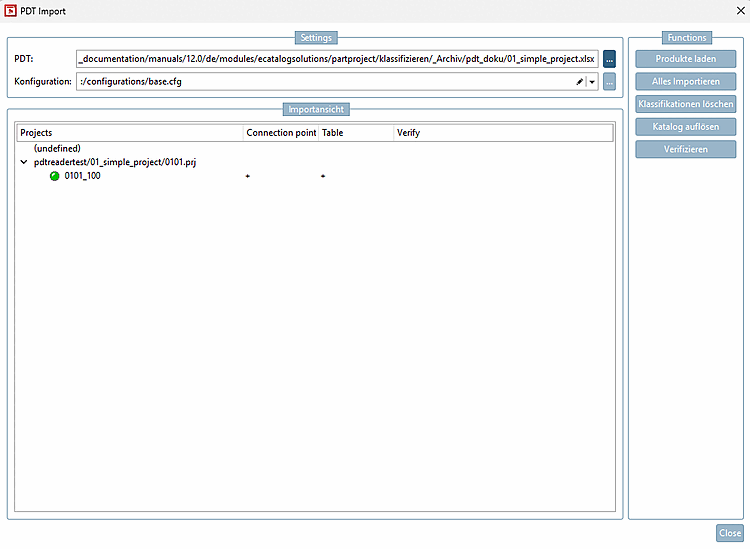
Configuration: In the list box, select
:/configurations/base.cfg.: The point has been omitted compared to V12.9, as the accessory is written via the relative path and not the POOL Id.
The checkboxes at the bottom have been removed compared to V12.9:
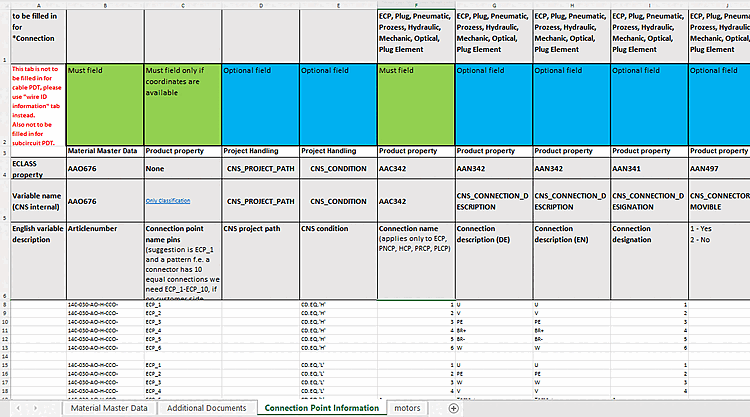
Do not use a search [Do not use search] via the new button . As long as the order number and there are no variants, it is not needed. In the case of yellow fields (value ranges), the function a resolution of the variants can be started. Order numbers of the Variants end up in a cache (
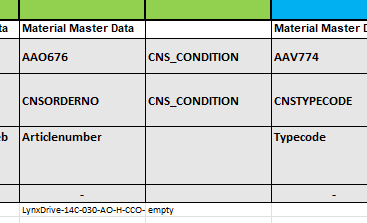
$CADENAS_USER/pdt_import/cache.json), which is then used to identify the correct lines becomes. As long as the catalog does not change, this is only once necessary.is mapped via the PDT file and a CNS_CONDITION column. If classifications are to apply to the entire project file ("entire" means for all values of the value range variables), a CNS_CONDITION with the value "empty" must be set (possible in all relevant tables).
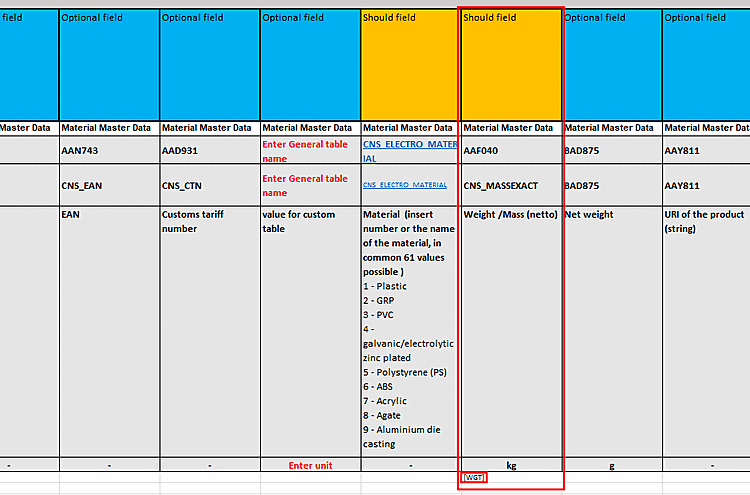
Combining attributes [Combine attributes] is completely unnecessary. If you want fields with algorithms(in the example below it is not an algorithm, is it?), the recommended way is to enter them manually in the table and use square brackets in the PDT to instruct the importer to refer to the corresponding column [COLUMN NAME] -> Classification refers to the table column COLUMN NAME.
Remove old classifications during import: This can be mapped after loading the products using the new button. All classifications with an instance name beginning with "PDT_" are deleted.
Process parametrically [Parametric processing]: Not applicable and is controlled via the CNS_CONDITION column of the Connection Point Information Excel table.
Other changes compared to V12.9:
The Debugging information is stored after each import under
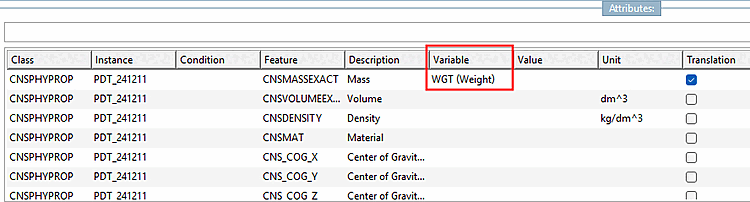
$CADENAS_USER/pdt_importloaded.In addition to the ECLASS property line, the variable name line is now also processed. While the first should be a unique ID (if it occurs twice, the first is regarded as the German and the second as the English translation of a field), the second should contain an attribute name so that it can be mapped directly to an attribute of a class. The mapping can be overridden in the configuration file. Ultimately, however, it would be optimal to have as much correct mapping as possible in the PDT template.
If 2 assemblies share the same subparts, already classified connection points are recognized and updated with the new values of the current import. If these are to have different values, assembly connection points must be used, as different values for points would only be possible in this case if they could be distinguished for their respective assembly via the CNS_CONDITION.
No specific tables need to be available to carry out an import. For example, an import can be made that imports only CP or only accessories.
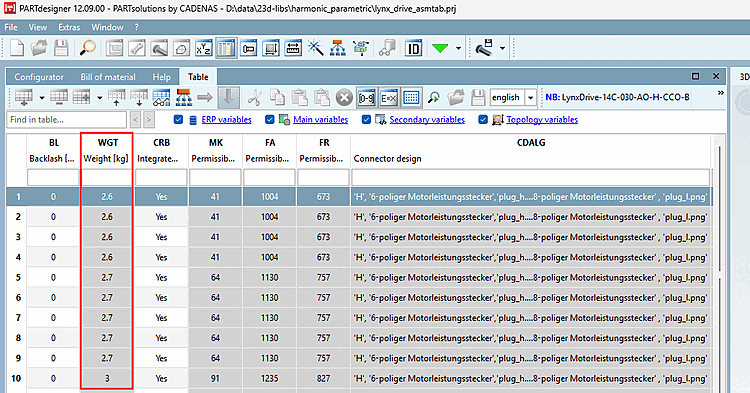
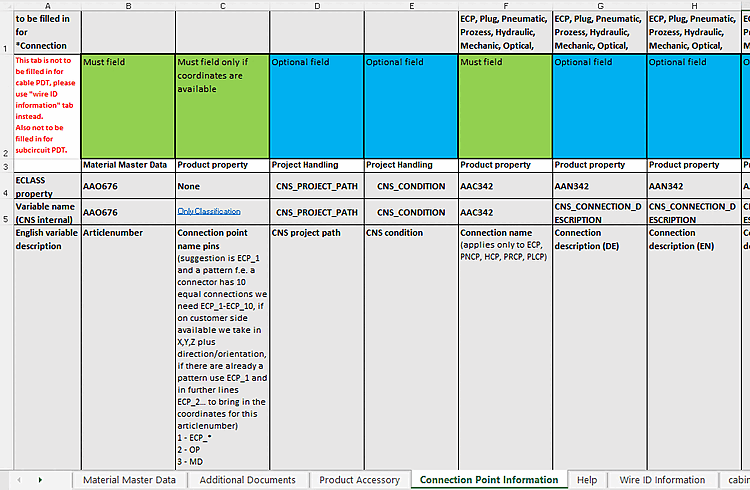
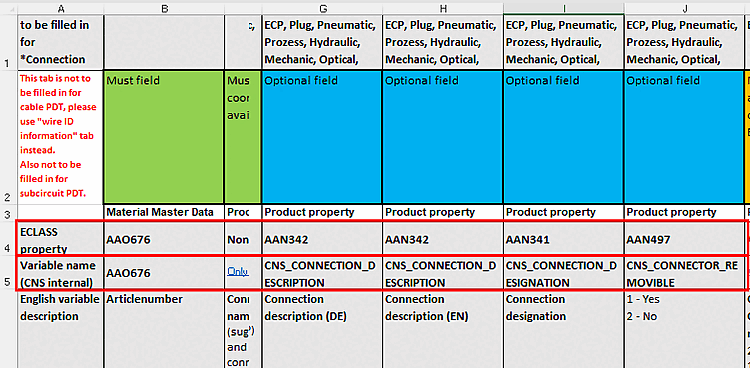
For assemblies, characteristics of classes that do not affect connection points are written to the assembly project (e.g. "CNSELEK"), characteristics of connection points ("CNS_CP") are written to the first subpart that has a connection point with the corresponding name.